1.2 What
MEDIATEX is mainly designed
to provides an API to manage supports (to drive jukeboxes).
As a distributed system,
it allows several servers to share data and meta-data
related to collections of archives.
MEDIATEX handle the TCP connections between remote servers.
It is designed to be installed directly on the archive producer’s application servers.
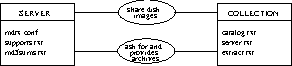
- External supports, are spreads geographically over all servers.
Supports was first designed to be optical disks,
but may also be a file you manually mount from what ever device
and file systems, or any locally hosted files.
Because on GNU/Linux there is a bug with last block on CD-ROM,
MEDIATEX use the ISO format image to retrieve the support size.
So, only the data disks are manage, not the audio ones for instance.
- Information on support’s images (what they contain and which servers provide them) is shared by all servers around the related collections.
- A single support may be used on several hosts,
for instance if we send it or if servers are located in the same place.
However, it is not recommended as MEDIATEX
will badly deduce that the support is duplicated.
- A support may be share locally around several collections.
- Servers are connected together via the internet public network and via
NAT gateway to reach hosts located on private networks.
- A server may participate to several collections.
- A server manages a local set of private supports including copies.
- Each MEDIATEX
system instance is located on a given host.
On a so call server, the
PUBLISHER (see Who) decides which support
are shared by which collection.
This association remains private and is not accessible remotely.
- Collections groups archives contained on supports
and make them available around the hosts that share the collection.
- A collection share support’s contents using there related hashes and sizes
(deduced from the ISO image for CDROM).
Collection also share extraction rules and content’s description
using a catalogue index.
- A collection should be shared by several servers,
at less 2 to prevent from a site crash.
All collection’s access parameters are shared around all the hosts
belonging to the collection.
Moreover, the collection concept is used to group document as
MEDIATEX
does not handle dedicated life cycle on archives.
What it is not.
MEDIATEX focus first on redundancy, done by software.
To do so:
- it isn’t using SGBD to handle meta-data but text files.
- it doesn’t do mirroring replication (rsync), but share caches locally and access them remotely (read only).
- is not a PHP application but it build a static WEB site and provides a CGI application based on a C library. (see Portail)
- is not based on a replicated SGBD but on a GIT repository.
- it doesn’t provide dynamic nor plain-text search. To do it you first have to export the meta-data into a database using the C library.
(see Linking)
- it doesn’t handle removal data from supports, which implies to re-burn CDs. It also does not provide a top API to remove meta-data.
- it isn’t SEDA or any XML exchange protocol compliant
(http://www.archivesdefrance.culture.gouv.fr/seda/index.html).
It can ever be interfaced with an upper layer server that will manage XML transactions and translations of meta-data. (see Linking)
- it doesn’t manage time-stamps.
(https://www.openssl.org/docs/manmaster/apps/ts.html).
Time-stamps or whatever additional meta-data files may still be provided and stored as data files.
- it doesn’t manage claim-based authentication or any “single sign on” mechanism
(https://en.wikipedia.org/wiki/OpenID).
However, APACHE2’s .htaccess file directives
may still be added to the related meta-data file to do so (example provided as sub project).
Time-stamps and claim-based authentication servers which need a static certificate and a static domain name are monolithic servers and so, resides out of this scope. MEDIATEX system is designed to be crashed anywhere but still alive elsewhere.