Copyright © Fran.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the file fdl-1.3.txt.
1. Introduction
JDosage2 is a webcomic downloader. It downloads comic images for offline reading, and enables opening images in custom viewers for easier reading. It can also be used by webcomic authors or webmasters to test their website for invalid links and missing images.
JDosage2 uses webcomic definitions to describe downloads, so it can be extended to support any webcomic. The program is cross-platform. It is written in Java, and works on GNU/Linux, Windows, Mac OS, and all other platforms where Java is supported. However, it is developed and tested primarily on GNU/Linux so, please, report any problems on other operating systems.
While there are other webcomic downloaders like Dosage, Woofy and Comica, I found none of them to be flexible enough, user friendly, and cross-platform. Also, writing my own downloader seemed like it would be fun. And it was.
|
|
Most webcomics are protected by copyright and unauthorized copying is prohibited. This program is intended for personal use only. If you intend to distribute the downloaded webcomics, be sure to verify that the webcomic license allows it. More importantly, by using JDosage2 to download webcomics for offline reading, you are skipping ads most webcomic authors use to make money from the website. If you like a webcomic, support it: click an ad, make a donation, or buy a book. |
2. Requirements
JDosage2 requires Java 6 or above. Also, I recommend GNU/Linux. Not for running this program, but generally.
3. Download
Latest version, as well as previous releases, are available here.
4. Quick start
jdosage2.jar is a Java executable. Run it by invoking java -jar jdosage2.jar from the Terminal or Command Prompt. This will print usage instructions and create default configuration in the base directory. For a more detailed description of program options, see Command line parameters.
Before downloading your first webcomic, open the configuration file, <base_dir>/config.properties, in a text editor and set download.dir to your webcomic download directory. Other configuration options are described in Configuration, but defaults should be fine for now.
To download a webcomic, first you need to create a webcomic definition. It is a text file that contains all the parameters needed for downloading comic images. As an example, we will create a webcomic definition for xkcd: A webcomic of romance, sarcasm, math, and language by Randall Munroe.
In the definitions directory, <base_dir>/webcomics, create a new file named xkcd.wcd and open it in a text editor. Add a comment and two entries: name and homepage.
# xkcd: A webcomic of romance, sarcasm, math, and language
name=xkcd
homepage=http://www.xkcd.comNext, create the comic selector. If you are using Firefox, right click on the image, choose Inspect Element and press Alt+M to show the markup panel. In Chrome, choose Inspect Element to open Developer Tools. In Internet Explorer, go to http://www.firefox.com and download Mozilla Firefox, or go to http://www.google.com/chrome and download Google Chrome.
You should see something similar to this.
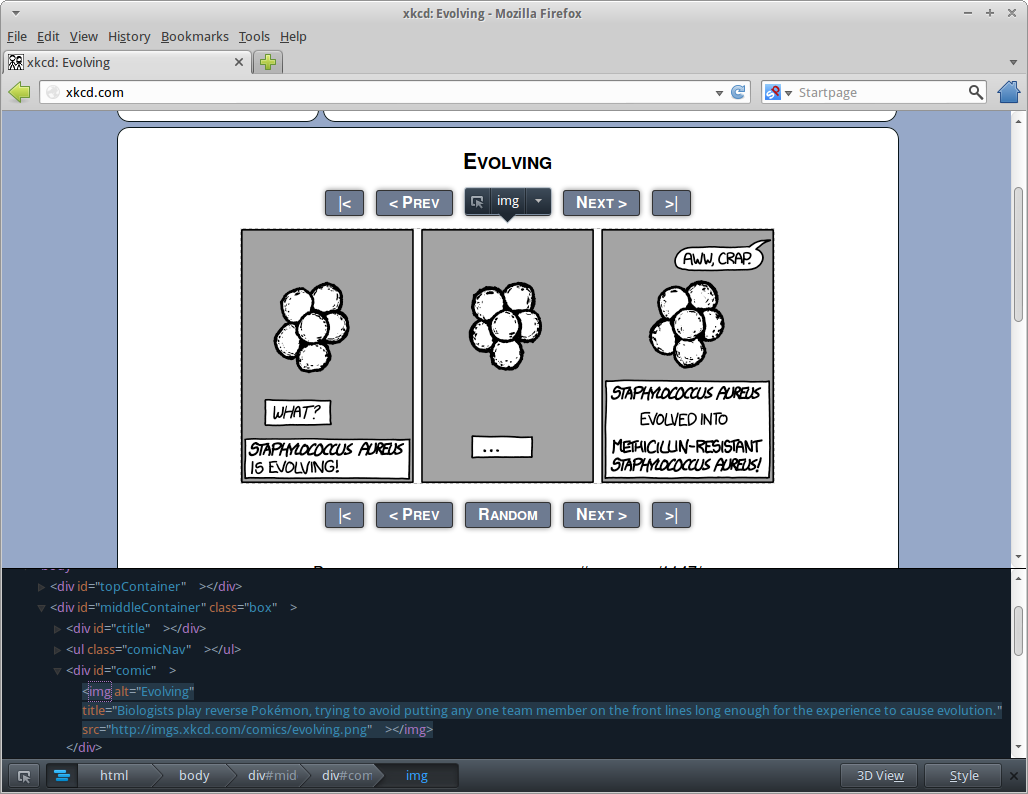
As you can see, the comic image is inside a div element with id=comic. This is a good marker because ids in HTML are (or at least should be) unique. Add the comic selector entry.
# matches all images inside the 'comic' div
comic=div#comic imgThis is probably the best selector for this case, but there are other possibilities that would also work.
# matches images inside the 'comic' div located inside the 'middleContainer' div
# unnecessarily extended
comic=div#middleContainer div#comic img# matches the outer 'middleContainer' div by class (non-unique), instead of id
comic=div.box div#comic img# matches images with URL starting with 'http://imgs.xkcd.com/comics/'
# URL matching is not the preferred method, but some webcomic pages leave no alternative
comic=img[src^=http://imgs.xkcd.com/comics/]|
|
#<id> and .<class> are shorthand for [id=<id>] and [class=<class>]. Any other HTML attribute can also be matched with this syntax.
|
Next, we need to create a file template for the saved images. If fileTemplate entry is not present, default value is used.
# fileTemplate=${name}/${filename}.${fileExt}
# this comic will be saved to <download_dir>/xkcd/evolving.pngThis is not good because the image filename does not contain a comic index or date, making chronological file sorting impossible. Go to the previous comic. The URL is now http://www.xkcd.com/1146/, and contains the comic index. If you go to the next comic, you will see Evolving again, but this time the URL http://www.xkcd.com/1147/ will contain the comic index. This means xkcd needs to be downloaded from the first webcomic forward, so the final comic will also have an indexed URL.
Create the file template using index from the webpage URL.
# index is extracted as the string after the third '/', and left padded with '0'
fileTemplate=${name}/${pageUrl?split("/")[3]?left_pad(4, "0")} - ${filename}.${fileExt}
# this comic will be saved to <download_dir>/xkcd/1147 - evolving.png# index is extracted as the first sequence of numbers in the URL, and left padded with '0'
# regex matching is more complex than fixed character splitting, but much more powerful
fileTemplate=${name}/${pageUrl?matches("[0-9]+")[0]?left_pad(4, "0")} - ${filename}.${fileExt}
# this comic will be saved to <download_dir>/xkcd/1147 - evolving.pngBecause xkcd will be downloaded starting from the first page, add firstPage entry for the download starting point. The difference between firstPage and lastPage starting points is explained in the Definition properties.
firstPage=http://www.xkcd.com/1/Finally, you need to add the selector for the next page link. Selector syntax is same as for the comic selector. The selector can match multiple links, but only if they point to the same URL. This is because some comics have a top and bottom navigation bar with similar elements. Select Inspect Element on the next page link.
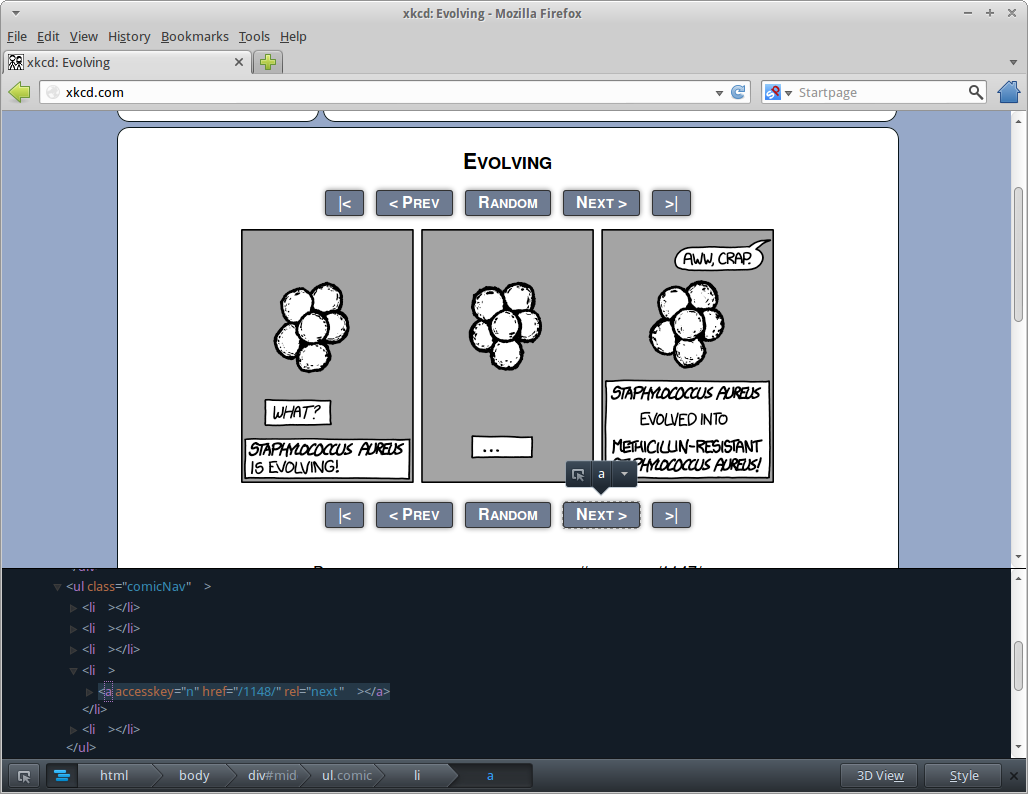
rel=next seems like a good marker for the next page link.
# matches links having rel=next
nextPage=a[rel=next]You can also match links by inner text or image.
# matches links directly containing the text 'Next >'
nextPage=a:containsOwn(Next >)# matches links containing image prev.png
nextPage=a:has(img[src=prev.png])Your xkcd webcomic definition is now complete.
# xkcd: A webcomic of romance, sarcasm, math, and language
name=xkcd
homepage=http://www.xkcd.com
comic=div#comic img
fileTemplate=${name}/${pageUrl?split("/")[3]?left_pad(4, "0")} - ${filename}.${fileExt}
firstPage=http://www.xkcd.com/1/
nextPage=a[rel=next]To start the download, run java -jar jdosage2.jar --download xkcd. The console will display download progress. You can stop the download at any time by pressing Ctrl+C. Next time, the download will continue from the point where it was interrupted.
If something goes wrong and you need more details, open the log file in <base_dir>/log and check the detailed output. Log file verbosity is set by log.level.file configuration entry.
5. Configuration
JDosage2 base directory is .jdosage2, located in the user home directory. This directory contains configuration, webcomic definitions and download logs.
User home directory is normally:
-
/home/<username> on UNIX or GNU/Linux
-
C:\Documents and Settings\<username> on Windows XP or older
-
C:\Users\<username> on Windows Vista or newer
Configuration file config.properties is located in the base directory. The syntax is very simple: entries are name/value pairs and comments are prefixed by a hash mark. This is the default configuration:
#JDosage2 configuration
#Thu Oct 11 11:34:35 CEST 2012
download.dir=/home/fran/Webcomics
connection.timeout=10
connection.retries=3
log.level.console=INFO
log.level.file=DEBUG5.1. Configuration parameters
This is the complete list of supported configuration parameters. Unknown entries are ignored.
Webcomic download directory. Default value is <user_home>/Webcomics. If you are a Windows user, you will probably want to change this to your Documents or Downloads folder.
HTTP connection timeout in seconds. Default value is 10. Increase if you have a slow or unstable Internet connection.
Number of download retries in case of a timeout or a connection error. Default value is 3.
Log level of console output. Default value is INFO. Set to DEBUG or TRACE when testing new webcomic definitions.
Log level for the file log. Default level is DEBUG. Log files are located in the <base_dir>/log.
5.2. Log levels
-
ALL- log everything (essentially same asTRACE) -
TRACE- log very detailed webcomic processing information, useful for debugging webcomic definitions -
DEBUG- log less detailed webcomic processing information -
INFO- log general information and comic downloads -
WARN- log webcomic processing errors and external errors only -
ERROR- log external errors only -
OFF- log nothing
6. Webcomic definitions
Webcomic definition files are located in <base_dir>/webcomics. To add a webcomic definition, create a new text file with wcd extension. Definition creation is described in Quick start.
6.1. Groups
Webcomic definition files can be grouped in subdirectories inside the webcomics directory. When downloading webcomics, --group parameter accepts group names to simplify multiple selection.
Every subdirectory in the webcomics directory tree is considered a group, and webcomics can belong to multiple groups. All valid directory names are valid group names, but I suggest using short names without spaces.
Examples:
-
webcomics/xkcd.wcd does not belong to any group
-
webcomics/biweekly/xkcd.wcd belongs to group biweekly
-
webcomics/great/biweekly/xkcd.wcd belongs to groups great and biweekly
-
webcomics/biweekly/great/xkcd.wcd also belongs to groups great and biweekly, and is equvalent to the previous example
6.2. Definition properties
- name
-
Webcomic name is mandatory. It is usually used in file templates, so avoid non-ASCII characters.
- homepage
-
Webcomic homepage is optional and not used when downloading comics. If it is set, it must be a valid URL.
- fileTemplate
-
Comic file template is used to generate the path of the image file. Default value is ${name}/${filename}.${fileExt}. For more details on file template syntax see File templates.
- lastPage
-
URL of the last comic webpage. If it is set, new downloads start from the last page, and download progress is cleared when download is finished. This is the preferred method because new downloads do not depend on previously saved progress to continue. If both first and last page are set,
lastPageis used andfirstPageis ignored. - firstPage
-
URL of the first comic webpage. If it is set, new downloads start from the last downloaded comic. Download progress is saved and never cleared. Used when the latest comic cannot be reached directly through a static URL.
- comic
-
Selector for comic images. Results must be images or links to image files. For more details on selector syntax see Selectors.
- nextPage
-
Selector for the next webcomic page. Result must be a link. Multiple results are accepted only if they are links pointing to the same URL. Selector syntax is same as for
comic.
6.3. File templates
When a comic image is downloaded, file template is used to generate the path and filename of the image file. File templates are always resolved relative to the download directory.
File templates are FreeMarker templates. Some examples are given in the Quick start guide. See FreeMarker manual for details on syntax and advanced usage examples.
The following variables are available in file templates:
-
name - name of the webcomic
-
imageUrl1 - url of the comic image
-
filename - comic image filename, without file extension
-
fileExt - comic image file extension
-
pageUrl1 - url of the current webpage
-
pageTitle2 - HTML title of the current webpage
-
imageText2 - comic image alt text, or link text if the image is linked
-
URL is decoded from the
application/x-www-form-urlencodedformat. -
HTML entities are decoded, and text trimmed. Concurrent whitespace characters are replaced with a single space. Illegal filename characters |, \, ?, *, <, ", :, >, +, [, ] and / are replaced with an underscore.
|
|
In file templates always use / as path separator, even on Windows. It will be converted to the platform-dependent path separator when file templates are rendered. |
6.4. Selectors
Selectors are expressions for matching HTML elements. They are used to find image and link tags when processing comic webpages.
JDosage2 uses JSoup selectors, which are similar to CSS selectors. For full syntax and examples, see JSoup documentation on selector syntax.
7. Download algorithm
JDosage2 scrapes webpage HTML to find comic images and page links. Download algorithm works as follows:
-
get the current webpage URL from the saved download progress,
lastPageorfirstPage -
download the webpage
-
find images and links to images matching the
comicselector-
if no comics are found → stop download with error
-
download found comics
-
if a comic image file already exists and webcomic is downloaded from the
lastPagebackwards → clear progress and stop download
-
-
-
find the link matching
nextPageselector-
if no next page link is found
-
if downloading from the
lastPagebackwards → clear progress -
stop download
-
-
update download progress with the new URL
-
-
repeat until a stop condition occurs or the program is terminated by user
8. Running the program
JDosage2 is a command line program. To start it, execute java -jar jdosage2.jar from the Terminal or Command Prompt. Run the program without parameters to see a list of parameters with their descriptions. To stop the program, terminate it by pressing Ctrl+C.
8.1. Command line parameters
- --list
-
List all webcomics matching filename or group filters. If no filters are specified, list all webcomics. Webcomic definitions are validated on load, so use this to test new definitions.
- --download
-
Download new comics for webcomics matching filename or group filters. If no filters are specified, download all new comics.
- --webcomic <filename(s)>
-
Filter webcomics by one or more webcomic definition filenames. Filenames are case insensitive, and are given without the file extension.
- --group <group(s)>
-
Filter webcomics by one or more groups. See Groups for details. Group names are case insenstive.
- --ignoreexisting
-
Do not stop the download if an existing comic image file is found.
- --ignoremissing
-
Do not stop the download if a webpage contains no comic images.
9. Future
|
|
Version {revision} is alpha, and although there are no major changes planned for the next stable release, beta and final version may break existing webcomic definitions. |
-
Download algorithm tweaks
-
Better logging
-
Expanded manual, more examples
-
Online webcomic definition repository
-
GUI
-
Concurrent downloading
-
Installer
10. Appendix A: License
JDosage2 Copyright © 2012 Fran
This program comes with ABSOLUTELY NO WARRANTY.
This is free software, and you are welcome to redistribute it
under certain conditions; see license.txt for details.
Apache Commons CLI - Apache License Version 2.0, http://commons.apache.org/cli/
Apache Commons IO - Apache License Version 2.0, http://commons.apache.org/io/
Apache Commons Lang - Apache License Version 2.0, http://commons.apache.org/lang/
FreeMarker - BSD-style license, http://freemarker.sourceforge.net/
JavaMail API - GNU General Public License Version 2, http://www.oracle.com/technetwork/java/javamail/index.html
JSoup - MIT License, http://jsoup.org/
Logback - GNU Lesser General Public License Version 2.1, http://logback.qos.ch/
Slf4j - MIT License, http://www.slf4j.org/
Asciidoc - GNU General Public License Version 2, http://www.methods.co.nz/asciidoc/
GNU Source-highlight - GNU General Public License Version 3, http://www.gnu.org/software/src-highlite/
11. Release notes
-
Replaced webcomic selection by wildcards with filename and group filters
-
Updated manual and build script
-
Initial release