
Contents:
Introduction
Modern Architectures
POOMA's Parallel Execution Model
Optimization
Templates
The Standard Template Library
Expression Templates
Object-oriented programming languages like C++ make development easier, but performance tuning harder. The same abstractions that allow programmers to focus on what their program is doing, rather than how it is doing it, also make it harder for compilers to re-order operations, predict how many times a loop will be executed, or re-use an area of memory instead of making an unnecessary copy.
For example, suppose that a class FloatVector is being used to store and operate on vectors of floating-point values. As well as constructors, a destructor, and element access methods, this class also has overloaded operators that add, multiply, and assign whole vectors:
class FloatVector
{
public :
FloatVector(); // default constructor
FloatVector( // value constructor
int size, // ..size of vector
float val // ..initial element value
);
FloatVector( // copy constructor
const FloatVector& v // ..what to copy
);
virtual ~FloatVector(); // clean up
float getAt( // get an element
int index // ..which element to get
) const;
void setAt( // change an element
int index, // ..which element to set
float val // ..new value for element
);
FloatVector operator+( // add, creating a new vector
const FloatVector& right // ..thing being added
);
FloatVector operator*( // multiply (create result)
const FloatVector& right // ..thing being multiplied
);
FloatVector& operator=( // assign, returning target
const FloatVector& right // ..source
);
protected :
int len_; // current length
float* val_; // current values
};
Look closely at what happens when a seemingly-innocuous statement like the following is executed:
FloatVector V, W, X, Y; // initialization V = W * X + Y;
W*X creates a new FloatVector, and fills it with the elementwise product of W and X by looping over the raw block of floats encapsulated by those two vectors. The call to the addition operator then creates another temporary FloatVector, and executes another loop to fill it. The call to the assignment operator doesn't create a third temporary, but does execute a third loop. The net result is that our statement does the equivalent of the following code:
FloatVector V, W, X, Y;
// initialization
FloatVector temp_1;
for (int i=0; i<vector_size; ++i)
{
temp_1.setAt(i, W.getAt(i) * X.getAt(i));
}
FloatVector temp_2;
for (int i=0; i<vector_size; ++i)
{
temp_2.setAt(i, temp_1.getAt(i) + Y.getAt(i));
}
for (int i=0; i<vector_size; ++i)
{
V.setAt(i, temp_2.getAt(i));
}
Clearly, if this program was written in C instead of C++, the three loops would have been combined, and the two temporary vectors eliminated, to create the more efficient code shown below:
FloatVector V, W, X, Y;
// initialization
for (int i=0; i<vector_size; ++i)
{
V.setAt(i, W.getAt(i) * X.getAt(i) + Y.getAt(i));
}
Turning the compact C++ expression first shown into the single optimized loop shown above is beyond the capabilities of existing commercial compilers. Because operations may involve aliasing---i.e., because an expression like V=W*X+V can assign to a vector while also reading from it---optimizers must err on the side of caution, and neither eliminate temporaries nor fuse loops. This has led many programmers to believe that C++ is intrinsically less efficient than C or Fortran 77, and that however good object-oriented languages are for building user interfaces, they will never deliver the performance needed for modern scientific and engineering applications.
The good news is that this conclusion is wrong. By making full use of the features of the new ANSI/ISO C++ standard, the POOMA library can give a modern C++ compiler the information it needs to compile C++ programs that achieve Fortran 77 levels of performance. What's more, POOMA does not sacrifice either readability or usability in order to achieve this: in fact, POOMA programs are more portable, and more readable, than many of their peers.
In order to understand how and why POOMA does what it does, it is necessary to have at least some understanding of the architecture of a modern RISC-based computer, how compilers optimize code, and what C++ templates can and cannot do. The sections below discuss each of these topics in turn.
One of the keys to making modern RISC processors go fast is extensive use of caching. A computer uses a cache to exploit the spatial and temporal locality of most programs. The former term means that if a process accesses address A, the odds are good that it will access addresses near A shortly thereafter. The latter means that if a process accesses a value, it is likely to access that value again shortly thereafter. An example of spatial locality is access to the fields of record structures in high-level languages; an example of temporal locality is the repeated use of a loop index variable to subscript an array.
Since the extra hardware that makes a cache fast also makes it expensive, modern computer memory is organized as a set of increasingly large, but increasingly slow, layers. For example, the memory hierarchy in a 500MHz DEC 21164 Alpha typically looks like this:
| Register | 2ns |
| L1 on-chip cache | 4ns |
| L2 on-chip cache | 15ns |
| L3 off-chip cache | 30ns |
| Main memory | 220ns |
Caches are usually built as associative memories. In a normal computer memory, a location is accessed by specifying its physical address. In an associative memory, on the other hand, each location keeps track of its own current logical address. When the processor tries to read or write some address A, each cache location checks to see whether it is supposed to respond.
In practice, some restrictions are imposed. The associativity is often restricted to sets of two, four or eight, so that every cache line isn't eligible to cache every possible memory reference. The values in a cache are then usually grouped into lines containing from four to sixteen words each. Together, these bring the cost down---the cost of each piece of address-matching hardware is amortized over several cache locations---but can also lead to thrashing: if a program tries to access values at regularly-spaced intervals, it could find itself loading a cache line from memory, using just one of the values in the line, and then immediately replacing that whole line with another one. One of the key features of POOMA is that it reads and writes memory during vector and matrix operations in ways that are much less likely to lead to thrashing. While this makes the implementation of POOMA more complicated, it greatly increases its performance.
At the same time as some computer architects were making processors simpler, others were making computers themselves more complex by combining dozens or hundreds of processors in a single machine. The simplest way to do this is to just attach a few extra processors to the computer's main bus. Such a design allows a lot of pre-existing software to be recycled; in particular, since most operating systems are written so that process execution may be interleaved arbitrarily, they can often be re-targeted to multiprocessors with only minor modifications. Similarly, if a loop performs an operation on each element of an array, and the operations are independent of one another, then each of P processors can run 1/P of the loop iterations independently.
The weakness of shared-bus multiprocessors is the finite bandwidth of the bus. As the number of processors increases, the time each one spends waiting to use the bus also increases. To date, this has limited the practical size of such machines to about two dozen processors.
Today's answer to this problem is to give each processor its own memory, and to use a network to connect those processor/memory nodes together. One advantage of this approach is that each node can be built using off-the-shelf hardware, such as a PC motherboard. Another advantage is that each processor's reads or writes of its own memory will be very fast. Remote reads and writes may either be done automatically by system software and hardware, or explicitly, using libraries such as PVM and MPI. So long as there is sufficient locality in programs---i.e., so long as most references are local---this scheme can deliver very high performance.
Of course, distributed-memory machines have problems too. In particular, once memory has been divided up in this way, all pointers are not created equal. On a distributed memory machine with global addressing (such as an SGI Origin 2000), dereferencing a pointer to remote memory will be considerably slower than local memory. On a distributed memory machine without global addressing (like a cluster of Linux boxes), a pointer cannot safely be passed between processes running on different processors. Similarly, if a data structure such as an array has been decomposed, and its components spread across the available processors so that each may work on a small part of it, a small change to an algorithm may have a large effect on performance. Another of POOMA's strengths is that it automatically manages data distribution to achieve high performance in a nonuniform shared memory machine. This not only lets programmers concentrate on algorithmic issues, it also saves them from having to learn the quirks of the architectures they want to run their programs on.
In order to be able to cope with the variations in machine architecture noted above, POOMA's parallel execution model is defined in terms of one or more contexts, each of which may host one or more threads. A context is a distinct region of memory in some computer. The threads associated with the context can access data in that memory region and can run on the processors associated with that context. Threads running in different contexts cannot access memory in other contexts.
A single context may include several physical processors, or just one. Conversely, different contexts do not have to be on separate computers---for example, a 32-node SMP machine could have up to 32 separate contexts. This release of POOMA only supports a single context for each application, but can use multiple threads in the context on supported platforms. Support for multiple contexts will be added in an upcoming release.
Along with interpreting the footnotes in various language standards, inventing automatic ways to optimize programs is a major preoccupation of today's compiler writers. Since a program is a specification of a function mapping input values to outputs, it ought to be possible for a sufficiently clever compiler to find the sequence of instructions that would calculate that function in the least time.
In practice, the phrase "sufficiently clever" glosses over some immense difficulties. If computer memories were infinitely large, so that no location ever needed to be used more than once, the task would be easier. However, programmers writing Fortran 77 and C++ invariably save values from one calculation to use in another (i.e., perform assignments), use pointers or index vectors to access data structures, or use several different names to access a single data structure (such as segments of an array). Before applying a possible optimization, therefore, a compiler must be able to convince itself that the optimization will not have unpleasant side effects.
To make this more concrete, consider the following sequence of statements:
A = 5 * B + C; // S1
X = (Y + Z) / 2; // S2
D = (A + 2) / E; // S3
C = F(I, J); // S4
A = I + J; // S5
if (A < 0) // S6
{
B = 0;
}
S1 and S2 are independent, since no variable appears in both. However, the result of S3 depends on the result of S1, since A appears on the right hand side of S1. Similarly, S4 sets the value of C, which S1 uses, so S4 must not take place before S1 has read the previous value of C. S5, which also sets the value of A, depends on S1, since S1 must not perform its assignment after S5's if the result of the program are to be unchanged. Finally, S6 depends on S5 because a value set in S5 is used to control the behavior of S6.
While it is easy to trace the relationships in this short program by hand, it has been known since the mid-1960s that the general problem of determining dependencies among statements in the presence of conditional branches is undecidable. The good news is that if all we want are sufficient, rather than necessary, conditions---i.e. if erring on the side of caution is acceptable---then the conditions which Si and Sj must satisfy in order to be independent are relatively simple.
This analysis becomes even simpler if we restrict our analysis to basic blocks. A basic block is a sequence of statements which can only be executed in a particular order. Basic blocks have a single entry point, a single exit point, and do not contain conditional branches or loop-backs. While they are usually short in systems programs like compilers and operating systems, most scientific programs contain basic blocks which are hundreds of instructions long. One of the aims of POOMA is to use C++ templates to make it easier for compilers to find and optimize basic blocks. In particular, as templates are expanded during compilation of POOMA programs, temporary variables that can confuse optimizers are automatically eliminated.
Another goal of POOMA's implementation is to make it easier for compilers to track data dependencies. In C++, an array is really just a pointer to the area of memory that has been allocated to store the array's values. This makes it easy for arrays to overlap and alias one another, which is often useful in improving performance, but it also makes it very difficult for compilers to determine when two memory references are, or are not, independent.
For example, suppose we re-write the first three statements in the example above as follows (using the '*' notation of C++ to indicate a pointer de-reference):
*A = *B + *C; // T1 *X = (*Y + *Z) / 2; // T2 *D = (*A + 2) / *E; // T3
In the worst case, all eight pointers could point to the same location in memory, which would make this calculation equivalent to:
(where J is the value in that one location). At the other extreme, each pointer could point at a separate location, which would mean that the calculation would have a completely different result. Again, as templates are expanded during the compilation of POOMA programs, the compiler is automatically given the extra information it needs to discriminate between cases like these, and thereby deliver better performance.J = 2 * (J + 1) / J;
So what exactly is a C++ template? One way to look at them is as an improvement over macros. Suppose, for example, that you wanted to create a set of classes to store pairs of ints, pairs of floats, and so on. In C, or pre-standardization versions of C++, you might first define a macro:
#define DECLARE_PAIR_CLASS(name_, type_) \
class name_ \
{ \
public : \
name_(); // default constructor \
name_(type_ left, type_ right); // value constructor \
name_(const name_& right); // copy constructor \
virtual ~name_(); // destructor \
type_& left(); // access left element \
type_& right(); // access right element \
\
protected : \
type_ left_, right_; // value storage \
};
You could then use that macro to create each class in turn:
DECLARE_PAIR_CLASS(IntPair, int) DECLARE_PAIR_CLASS(FloatPair, float)
A better way to do this in standard C++ is to declare a template class, and then instantiate that class when and as needed:
template<class DataType>
class Pair
{
public :
Pair(); // default constructor
Pair(DataType left, // value constructor
DataType right);
Pair(const Pair<DataType>& right); // copy constructor
virtual ~Pair(); // destructor
DataType& left(); // access left element
DataType& right(); // access right element
protected :
DataType left_, right_; // value storage
};
Here, the keyword template tells the compiler that the class cannot be compiled right away, since it depends on an as-yet-unknown data type. When the declarations:
Pair<int> pairOfInts; Pair<float> pairOfFloats;
are seen, the compiler finds the declaration of Pair, and instantiates it once for each underlying data type.
Templates can also be used to define functions, as in:
template<class DataType>
void swap(DataType& left, DataType& right)
{
DataType tmp(left);
left = right;
right = tmp;
}
Once again, this function can be called with two objects of any matching type, without any further work on the programmer's part:
int i, j; swap(i, j); Shape back, front; swap(back, front);
Note that the implementation of swap() depends on the actual data type of its arguments having both a copy constructor (so that tmp can be initialized with the value of left) and an assignment operator (so that left and right can be overwritten). If the actual data type does not provide either of these, the particular instantiation of swap() will fail to compile.
Note also that swap() can be made more flexible by not requiring the two objects to have exactly the same type. The following re-definition of swap() will exchange the values of any two objects, provided appropriate assignment and conversion operators exist:
template<class LeftType, class RightType>
void swap(LeftType& left, RightType& right)
{
LeftType tmp(left);
left = right;
right = tmp;
}
Finally, the word class appears in template definitions because any valid type, such as integers, can be used. The code below defines a template for a small fixed-size vector class, but does not fix either the size or the underlying data type:
template<class DataType, int FixedSize>
class FixedVector
{
public :
FixedVector(); // default constructor
FixedVector(DataType filler); // value constructor
virtual ~FixedVector(); // destructor
FixedVector( // copy constructor
const FixedVector<DataType, FixedSize>& right
);
FixedVector<DataType>& // assignment
operator=(
const FixedVector<DataType, FixedSize>& right
);
DataType& operator[](int index); // element access
protected :
DataType storage[FixedSize]; // fixed-size storage
};
It is at this point that the possible performance advantages of templated classes start to become apparent. Suppose that the copy constructor for this class is implemented as follows:
template<class DataType, int FixedSize>
FixedVector::FixedVector(
const FixedVector<DataType, FixedSize>& right
){
for (int i=0; i<FixedSize; ++i)
{
storage[i] = right.storage[i];
}
}
When the compiler sees a use of the copy constructor, such as:
template<class DataType, int FixedSize>
void someFunction(FixedVector<DataType, FixedSize> arg)
{
FixedVector<DataType, FixedSize> tmp(arg);
// operations on tmp
}
it knows the size as well as the underlying data type of the objects being manipulated, and can therefore perform many more optimizations than it could if the size were variable. What's more, the compiler can do this even when different calls to someFunction() operate on vectors of different sizes, as in:
FixedVector<double, 8> splineFilter; someFunction(splineFilter); FixedVector<double, 22> chebyshevFilter; someFunction(chebyshevFilter);
Automatic instantiation of templates is both convenient and powerful, but does have one drawback. Suppose the Pair class shown earlier is instantiated in each of two separate source files to create a pair of ints. The compiler and linker could:
The first of these can lead to very large programs, as a commonly-used template class may be expanded dozens of times. The second is difficult to do, as it involves patching up compiled files as they are being linked. Most recent versions of C++ compilers are therefore taking the third approach, but POOMA users should be aware that older versions might still produce much larger executables than one would expect.
The last use of templates that is important to this discussion is member templates, which are a logical extension of templated functions. This feature was added to the ANSI/ISO C++ standard rather late, but has proved to be very powerful. Just as a templated function is instantiated on demand for different types of arguments, so too are templated methods instantiated for a class when and as they are used. For example, suppose a class is defined as follows:
class Example
{
public :
Example(); // default constructor
virtual ~Example(); // destructor
template<class T>
void foo(T object)
{
// some operation on object
}
};
Whenever the method foo() is called with an object of a particular type, the compiler instantiates the method for that type. Thus, both of the following calls in the following code are legal:
Example e; Shape box; e.foo(5); // instantiate for int e.foo(box); // instantiate for Shape
The best-known use of templates to date has been the Standard Template Library, or STL. The STL uses templates to separate containers (such as vectors and lists) from algorithms (such as finding, merging, and sorting). The two are connected through the use of iterators, which are classes that know how to read or write particular containers, without exposing the actual type of those containers.
For example, consider the following code fragment, which replaces the first occurrence of a particular value in a vector of floating-point numbers:
void replaceFirst(vector<double> & vals, double oldVal, double newVal)
{
vector<double>::iterator loc =
find(vals.begin(), vals.end(), oldVal);
if (loc != vals.end())
*loc = newVal;
}
The STL class vector declares another class called iterator, whose job it is to traverse a vector. The two methods begin() and end() return instances of vector::iterator marking the beginning and end of the vector. STL's find() function iterates from the first of its arguments to the second, looking for a value that matches the third argument. Finally, dereferencing (operator*) is overloaded for vector::iterator, so that *loc returns the value at the location specified by loc.
If we decide later to store our values in a list instead of in a vector, only the declaration of the container type needs to change, since list defines a nested iterator class, and begin() and end() methods, in exactly the same way as vector:
void replaceFirst(list<double> & vals, double oldVal, double newVal)
{
list<double>::iterator loc =
find(vals.begin(), vals.end(), oldVal);
if (loc != vals.end())
*loc = newVal;
}
If we go one step further, and use a typedef to label our container type, then nothing in findValue() needs to change at all:
typedef vector<double> Storage;
// typedef list<double> Storage;
void replaceFirst(Storage<double> & vals, double oldVal, double newVal)
{
Storage<double>::iterator loc =
find(vals.begin(), vals.end(), oldVal);
if (loc != vals.end())
*loc = newVal;
}
The performance of this code will change as the storage mechanism changes, but that's the point: STL-based code can often be tuned using only minor, non-algorithmic changes. As the tutorials will show, POOMA borrows many ideas from the STL in order to separate interface from implementation, and thereby make optimization easier. In particular, POOMA's arrays are actually more like iterators, in that they are an interface to data, rather than the data itself. This allows programmers to switch between dense and sparse, or centralized and distributed, array storage, with only minor, localized changes to the text of their programs.
Parse trees are commonly used by compilers to store the essential features of the source of a program. The leaf nodes of a parse tree consist of atomic symbols in the language, such as variable names or numerical constants. The parse tree's intermediate nodes represent ways of combining those values, such as arithmetic operators and while loops. For example, the expression -B+2*C could be represented by the parse tree:
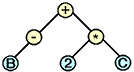
Parse trees are often represented textually using prefix notation, in which the non-terminal combiner and its arguments are strung together in a parenthesized list. For example, the expression -B+2*C can be represented as (+ (-B)(* 2 C)).
What makes all of this relevant to high-performance computing is that the expression (+ (-B)(* 2 C)) could equally easily be written BinaryOp<Add, UnaryOp<Minus, B>, BinaryOp<Multiply, Scalar<2>, C>>: it's just a different notation. However, this notation is very similar to the syntax of C++ templates --- so similar, in fact, that it can actually be implemented given a careful enough set of template definitions. As discussed earlier, by providing more information to the optimizer as programs are being compiled, template libraries can increase the scope for performance optimization.
Any facility for representing expressions as trees must provide:
C++ templates were not designed with these requirements in mind, but it turns out that they can satisfy them. The central idea is to use the compiler's representation of type information in an instantiated template to store operands and operators. For example, suppose that a set of classes have been defined to represent the basic arithmetic operations:
struct AddOp
{
static inline double apply(const double & x, const double & y)
{
return x + y;
}
};
struct MulOp
{
static inline double apply(const double & x, const double & y)
{
return x * y;
}
};
// ...and so on...
Note the use of the keyword struct; this simply signals that everything else in these classes---in particular, their default constructors and their destructors---are public.
Now suppose that a templated class BinaryOp has been defined as follows:
template<class Operator, class RHS>
class BinaryOp
{
public :
// empty constructor will be optimized away, but triggers
// type identification needed for template expansion
BinaryOp(
Operator op,
const Vector & leftArg,
const RHS & rightArg
) : left_(leftArg),
right_(rightArg)
{}
// empty destructor will be optimized away
~BinaryOp()
{}
// calculate value of expression at specified index by recursing
inline double apply(int i)
{
return Operator::apply(leftArg.apply(i), rightArg.apply(i));
}
protected :
const Vector & left_;
const RHS & right_;
};
If b and c have been defined as Vector, and if Vector::apply() returns the vector element at the specified index, then when the compiler sees the following expression:
BinaryOp<MulOp, Vector, Vector>(MulOp(), b, c).apply(3)
it translates the expression into b.apply(3) * c.apply(3). The creation of the intermediate instance of BinaryOp is optimized away completely, since all that object does is record a couple of references to arguments.
Why to go all this trouble? The answer is rather long, and requires a few seemingly-pointless steps. Consider what happens when the complicated expression above is nested inside an even more complicated expression, which adds an element of another vector a to the original expression's result:
BinaryOp< AddOp,
Vector,
BinaryOp< MulOp, Vector, Vector >
>(a, BinaryOp< MulOp, Vector, Vector >(b, c)).apply(3);
This expression calculates a.apply(3) + (b.apply(3) *c.apply(3)). If the expression was wrapped in a for loop, and the loop's index was used in place of the constant 3, the expression would calculate an entire vector's worth of new values:
BinaryOp< AddOp,
Vector,
BinaryOp< MulOp, Vector, Vector > >
expr(a, BinaryOp< MulOp, Vector, Vector >(b, c));
for (int i=0; i<vectorLength; ++i)
{
double tmp = expr.apply(i);
}
The possible nesting of BinaryOp inside itself is the reason that the BinaryOp template has two type parameters. The first argument to a BinaryOp is always a Vector, but the second may be either a Vector or an expression involving Vectors.
The code above is not something any reasonable person would want to write. However, having a compiler create this loop and its contained expression automatically is entirely plausible. The first step is to overload addition and multiplication for vectors, so that operator+(Vector,Vector) (and operator*(Vector,Vector)) instantiates BinaryOp with AddOp (and MulOp) as its first type argument, and invokes the apply() method of the instantiated object. The second step is to overload the assignment operator operator=(Vector,Vector) so that it generates the loop shown above:
template<class Op, T>
Vector & operator=(
Vector & target,
BinaryOp<Op> & expr
){
for (int i=0; i<vectorLength; ++i)
{
target.set(i, expr.apply(i));
}
return target;
}
With these operator definitions in play, the simple expression:
Vector x, a, b, c; // ...initialization... x = a + b * c;
is automatically translated into the efficient loop shown above, rather than into the inefficient loops shown earlier. The expression on the right hand side is turned into an instance of a templated class whose type encodes the operations to be performed, while the implementation of the assignment operator causes that expression to be evaluated exactly once for each legal index. No temporaries are created, and only a single loop is executed.
This may seem complicated, but that's because it is. POOMA,
and other libraries based on expression templates, push C++ to its
limits because that's what it takes to get high performance. Defining
the templated classes such a library requires is a painstaking task,
as is ensuring that their expansion produces the correct result, but
once it has been done, programmers can take full advantage of operator
overloading to create compact, readable, maintainable programs without
sacrificing performance.
| [Prev] | [Home] | [Next] |