 eLyXer User Guide
eLyXer User Guide
Alex Fernández (elyxer@gmail.com)
Table of Contents
1 The Basics
elixir, n: a substance believed to cure all ills[1].
eLyXer (pronounced elixir) is a LyX to HTML converter. While there are a ton of such projects all over the web, eLyXer has a clear focus on flexibility and elegant output.
eLyXer (including this guide and all accompanying materials) is licensed under the GPL version 3 or, at your option, any later version. See the LICENSE file for details.
Please visit the main page to find out about the latest developments.
1.1 System Requirements
eLyXer requires Python 2.4.x, and should work with versions up to 2.6.y; it will convert documents generated by LyX 1.5.x to 2.0. It has been tested on the most common operating systems: on Mac OS X, Linux and Windows, with and without CygWin.
Resource usage should be quite frugal; eLyXer runs quite happily on my 1st-gen Asus Eee, with its puny Celeron@570MHz and 512 MB of RAM. It should also be fast — the Eee can convert ~200 pages of LyX text in just over 50 seconds. Performance is fairly linear: 200 pages take 10 × as long as 20, so there are no scalability problems. Memory usage stays low even when processing large documents, and conversion can be done on the fly (with --lowmem) for even lower memory requirements.
1.2 Installation
This section looks at how to install eLyXer on your system, assuming that Python 2.4 to 2.6 is already there.
Download eLyXer
First you will need to fetch the official distribution file from the download area. Now, there is more than one way to install eLyXe, but all of them start by uncompressing the distributed file to a suitable directory. Just write at the command prompt:
$ tar -xzf elyxer-[version].tar.gz
Or for the .zip version:
$ unzip elyxer-[version].zip
A directory called elyxer should appear, where the main executable file elyxer.py resides.
Using the Installer
An installer is provided in the root directory, called install.py; it is the recommended way to install eLyXer. To run it just type in a console as root:
# python install.py
On Windows you can type (as a regular user):
> python.exe install.py
In any case, the script will install eLyXer as a Python script. Now you can check if it was installed successfully:
$ elyxer.py --help
A brief help text and the list of command line options should appear.
The installer will also copy existing translation files to your hard drive so that they can be used from within eLyXer for internationalization.
Prepackaged Versions
The easiest way to install eLyXer is if someone has prepackaged it for your system. Some Linux distributions include eLyXer: Debian squeeze and Ubuntu Lucid. Installation is done using apt-get or aptitude, for Debian as root:
# apt-get install elyxer
or, for Ubuntu:
$ sudo aptitude install elyxer
For both Debian and Ubuntu eLyXer needs to be run as "elyxer":
$ elyxer --help
On Windows, the alternate LyX installer includes eLyXer in the default installation. See 1.6↓ for LyX integration.
Manual Installation
If the installer did not work for you, you can manually install it as a module. On Linux go to the elyxer directory and type, as root:
# python setup.py install
On Windows just type:
> python.exe setup.py install
On Mac OS X you can use sudo to get the necessary permissions:
% sudo python setup.py install
Now you can run eLyXer as a Python script:
$ elyxer.py --help
The list of command line options should appear. You can also manually copy the file elyxer.py to a directory found in the execution path (for instance, /usr/bin on Linux or c:\windows\system32 on Windows).
1.3 Test Drive
Now you may want to try to convert the user guide:
$ elyxer.py --css lyx.css --title "eLyXer User Guide" docs/userguide.lyx docs/userguide2.html
It should generate a working web page identical to the one distributed:
$ diff docs/userguide.html docs/userguide2.html
The typical output will contain just the changed lines, which in this case should be only the header with the file creation date. An example is shown on listing 1↓.
If nothing else appears (i.e. both files are functionally equal) then everything is working fine. If you have bash installed, to test that everything really works fine you can just run the included tests:
$ ./run-tests
It will run a number of test and check the results, so you can see if everything is well. You also need to have installed the command-line tool diff to show differences between two files.
1.4 Usage
eLyXer is a standalone command line tool. It can be invoked from the command line as:
$ elyxer.py [options] [source file] [destination file]
If the source file is omitted then STDIN is used; likewise, if no destination file is specified eLyXer will output to STDOUT. This allows its use in pipes and other flexible configurations. Some examples:
$ elyxer.py file.lyx file.html
converts file.lyx to file.html. Debug messages are shown.
$ cat file.lyx | elyxer.py > file.html
converts file.lyx to file.html, as before. This time debug messages are not shown.
$ elyxer.py file.lyx | grep "<blockquote>" | wc
counts all blockquote paragraphs.
$ elyxer.py file.lyx | wget --no-check-certificate --spider -nv -F -i -
checks all external links in a document recursively. (Local links will appear as unresolved, but they can be ignored.)
1.5 Image Processing
eLyXer does not convert images directly; it uses the ImageMagick package, in particular the convert tool, to create PNG versions of the images embedded in the original LyX documents, and then it inserts links to those PNG images in the resulting HTML pages. If ImageMagick is not installed eLyXer will show an error message and will not try to convert further images.
HTML pages, unlike PDF documents, do not contain images in the document file; rather they contain pointers to image locations on disk. (Fortunately, LyX documents do not contain images either.) eLyXer will generate pages that point to the same locations as the original images, when they are PNG images, or to the converted versions otherwise. Image types like Encapsulated PostScript cannot be used directly from within pages.
Image location is fragile. All images should be placed in the same location (and with the same structure) as the original document; and they should all be referenced relatively to the current document. During conversion from within LyX image locations can be lost, since LyX does not do in-place conversion; instead, LyX copies the original file to a temporary directory, converts the file and then copies everything back to a directory ending in .LyXconv.
1.6 LyX Integration
If you used the eLyXer installer LyX will automatically detect it after reconfiguration. Just make sure that you are running LyX 1.6.5 or later, and click on Tools ▷ Reconfigure.
LyX should be able to detect if eLyXer was installed as a script, or even if it has been installed from a Linux distribution. In any case you can verify that it has been recognized by LyX by opening Tools ▷ Preferences…, going to External formats ▷ Converters, and finding the converter for “LyX -> HTML”. If eLyXer is there, it worked! Now you can convert your documents using View ▷ HTML. Otherwise try to reinstall eLyXer from scratch and then reconfigure LyX.
Installing as a Package or as a Module
Versions of the eLyXer installer prior to 1.2.0 tried to install eLyXer as a module, so it could be run using "python -m elyxer". This option is deprecated since a module called elyxer would collide with a Python package of the same name, and there are plans to install eLyXer as a proper Python package in the future (probably in the 1.3.0 time frame). In the interim eLyXer is installed only as a script called elyxer.py.
LyX (starting with versions 2.0.0 and 1.6.9) has been patched to recognize only the script and disregard the module.
2 Advanced Use
There are some advanced uses for eLyXer if you want to extract the most of it.
2.1 Command Line Options
eLyXer supports a few command line options:
--help: Show command line help.
--quiet: Be quiet and do not output messages (except errors). This way you can avoid the comforting “Parsing line 1000” messages. When STDIN or STDOUT are used (e.g. in a pipeline) --quiet is always enabled.
Advanced Options
--debug: Show debug messages. They may help a developer understand your problem.
--version: Show version number and date. Use to check which version you are actually running.
--lyxformat: Return the highest LyX version that eLyXer understands. This parameter is provided to help with lyx2lyx integration, so that this tool knows if it must convert the file to a lower LyX format.
Options to Control HTML output
--title "title": Change the title of the generated web page.
--css "new.css": Change default CSS. See section 2.2↓: CSS.
--embedcss "file.css": Embed the styles in file.css into the resulting HTML document. See section 2.2↓: CSS.
--html: Generate HTML 4.0 (instead of XHTML). The resulting pages should be easier to import from certain word processors. See section 2.6↓: HTML code.
--unicode: Restore full Unicode output. Right now switches midspaces to medium mathematical spaces. See also section 2.6↓: HTML code.
--iso885915: Generate a document using ISO-8859-1 encoding. Again, see section 2.6↓: HTML code.
--nofooter: Omit the footer message “Document generated by eLyXer” (shown at the bottom).
Options to Control image output
--directory "images_dir": Look for images in the directory specified.
--destdirectory "dest_dir": Converted images will end up into this directory.
--imageformat ".extension": Force the format implied by the extension (e.g. ".jpg" for JPEG) for output images. Use --imageformat "copy" to make images be copied over instead of converted.
--converter "program": Use the given program to convert images. Right now only two converters are supported: imagemagick (default) and inkscape. The latter chooses Inkscape as the image converter, instead of the default ImageMagick. Inkscape uses some non-standard extensions so it might be needed to convert SVG images to PNG.
--noconvert: Use all images in their original location and do not convert anything. Useful when using images which do not convert well, such as SVG files.
Options to Control footnote output
--numberfoot: Number all footnotes using numbers: “[1]”, instead of the default “[A]”.
--symbolfoot: mark footnotes with symbols (*, **, †, ‡…).
--hoverfoot: show footnotes as hovering text. This is the default position.
--marginfoot: show footnotes with numbers instead of letters.
--endfoot: show footnotes at the end of the page.
--supfoot: use superscript for footnote markers. This is the default style.
--alignfoot: use aligned text for footnote markers, instead of superscript.
--footnotes "options": specify several footnotes options at the same time, separated with commas. Available options are: "number", "hover", "margin", "end". See section 2.9↓: Footnotes.
Advanced Options to Control HTML output
--splitpart "depth": Split the resulting webpage at the given depth. See section 2.5↓: Segmenting Pages.
--tocfor "original.html": Generate just a table of contents with links to the original HTML file. See section 2.4↓: TOC.
--target "frame": Add a target attribute to every link in the generated HTML, making all links point to the provided frame. Again, see section 2.4↓: TOC.
--notoclabels: Omit “Chapter”, “Part” and similar labels from the TOC; just output part numbers (and separate using a period). For instance, a chapter that without this option is labeled “Chapter 2: Advanced Use” in the TOC would now become “2. Advanced Use”, as on the PDF. Option adapted from the wish list: 3.2↓.
--lowmem: Activate a low memory mode which does not keep the whole document in memory: conversion is done on the fly. Keep in mind that some features as the TOC will be missing from the generated document.
--numberfoot: Label footnotes using numbers, instead of letters. Useful when bibliographical references are not numbered and therefore cannot be confused with footnotes.
--raw: Generate an HTML page without header or footer.
--mathjax remote: Use the excellent JavaScript library MathJax remotely to pretty-print mathematical equations. See section 2.8↓.
--mathjax "URL": Use the excellent JavaScript library MathJax at the given URL (usually a local URL is used). See also section 2.8↓.
--simplemath: Do not generate fancy math structures such as multi-line Unicode brackets or stacked limits. This option is automatically activated when --html is selected; once more see section 2.8↓.
--template "file": Use an HTML template. The raw converted document will be placed where <!--$content--> appears in the template. Available variables: <!--$content-->, <!--$title-->, <!--$author-->, <!--$encoding-->, <!--$css-->, <!--$navigation-->, <!--$year-->, <!--$date-->, <!--$datetime-->, <!--$version-->, <!--$script-->, <!--$mathjax-->.
--copyright: Include a copyright notice at the bottom.
Deprecated Options
--toc: Generate just a table of contents. Use --tocfor instead.
--toctarget "original.html": Generate a table of contents with links to the original HTML file. Use --tocfor instead.
--nocopy: No effect since the copyright notice is now optional, maintained for backwards compatibility.
When an option accepts an argument it can be added after a space as --target "frame", or with an equals sign as in --target="frame". The quotes are optional and can be useful if your arguments include e.g. spaces.
Adding Options In LyX
To add one of these options so that it is used from within LyX, you have to modify the converter line. To this effect open Tools ▷ Preferences…, go to External formats ▷ Converters, find the converter for “LyX -> HTML” and edit the converter line. It should read something like this:
elyxer.py --directory $$r $$i $$o
If you want to generate pure HTML instead of XHTML, change the line to:
elyxer.py --html --directory $$r $$i $$o
And so on. Figure 1 shows what to do to add the --html option: after editing the line and adding the new option, click on “Modify” and then “Save” or “Apply” the changes.
You should never remove the $$i $$o at the end, since it is what tells eLyXer where to find the input and output files.
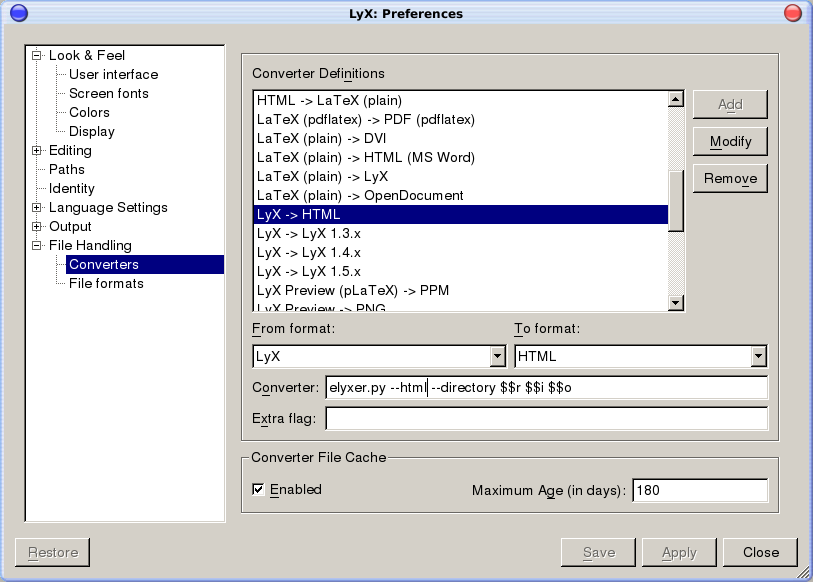
LyX 1.6.5 supports a new “extra flag” line; however, at this moment it does not work with eLyXer.
2.2 CSS
HTML output, as generated, can fall short in certain situations. Some CSS wizardry can go a long way to customize eLyXer.
eLyXer tags most elements with the type so you can later modify them using a CSS. The default HTML header is similar to listing 2↓, so the default remote CSS file is used.
This sample CSS file is published on nongnu.org and distributed along with the scripts, docs/lyx.css. (You may have found that your document shows minor changes in its appearance with time — this is the reason. The main author regularly publishes a new, updated version of lyx.css on nongnu.org, and all documents using it automatically appear with the changes. Backwards compatibility is maintained as much as possible.)
To give your document a customized appearance (or for pages to be accessible offline) you probably will want to use your own CSS file; to use it first copy it to the directory where your document resides (e.g. renaming it to custom.css), and customize as needed. Then run elyxer.py with the following option:
$ elyxer.py --css=custom.css document.lyx page.html
This will make the generated page.html use your custom.css file. The ‘=’ sign between the constant ‘--css’ and the name of the CSS file is optional. More than one --css option can be added if you want several CSS files to be used in the header.
Sometimes the styles in a CSS are needed in the HTML document (for offline viewing, or to distribute as stand-alone pages). For these uses there is the option --embedcss: the styles contained in the CSS file passed as an argument will be embedded in the resulting HTML document. For instance:
$ elyxer.py --embedcss custom.css document.lyx page.html
This command generates a document page.html where the styles in custom.css are embedded. The CSS to embed must be a file, not a remote URL. Listing 3↓ shows the resulting HTML header for a test CSS with just one style, div.Standard. Note that the remote CSS is still added by default; to avoid it just add an option with an empty CSS file, --css="".
As with the --css option, several --embedcss options can be added to embed more than one file.
The CSS file for eLyXer uses some CSS2 features for math structures (fractions, arrays). This makes the output incompatible with older browsers; it requires Microsoft Internet Explorer 7, Firefox 3, Safari 3 or Chrome 1. Check the Math Showcase to see if your browser can render eLyXer output correctly.
2.3 Title
By default the generated web pages have the title “Converted Document”. If a PDF title is found then it is used instead. The proper LyX title (a paragraph of type “Title” embedded in the text) will also be used if found. But when --lowmem is in use eLyXer does not try to get the proper title, since it may be found in the middle of the document or not be present at all; scanning for it would mean doing two passes, one to look for the title in all the document and another to output the web page, and --lowmem implies on-the-fly conversion to save memory.
You can change the title of the generated web page with the --title option:
$ elyxer.py --title "My Beautiful Document" document.lyx page.html
2.4 Table Of Contents
A table of contents (or TOC) can be generated for every converted LyX document. You can optionally also add a target frame to every link. The trick is to combine both options to generate a TOC that links to the original document on a different frame. For example, if the original page is called page.html and you generated it with this command:
$ elyxer.py document.lyx page.html
you can generate the TOC linking to this page, and at the same time point it to frame contents:
$ elyxer.py --tocfor page.html --target contents document.lyx page-toc.html
Then you can put it all together with a simple frameset generated manually. Just remember to place the original document in the frame called contents.
TOC generation accepts the same options as normal document conversion. For example, if you follow these instructions literally you will notice that the TOC has very wide margins and looks a bit weird; that is because it is using the default CSS. A special CSS file for TOC files is provided in docs/toc.css, so better results should be obtained with the --css option:
$ elyxer.py --tocfor page.html --css docs/toc.css --target contents document.lyx page-toc.html
With a little bit of practice you will be able to generate useful (and nice looking) TOC files. You can see an example for the user guide (if you are not already looking at it).
2.5 Segmenting Pages
Quite often you don’t want a huge monolithic page, but a set of linked pages. To do so you can use the --splitpart option, specifying the level at which eLyXer should split pages. For instance:
$ elyxer.py --splitpart 1 document.lyx output.html
will split document.lyx into pages at level 1, using output.html as the root page. Each page will get a number that starts with output and ends with .html, with a suffix that depends on the page — output-2.html will correspond to the second split part.
The level corresponding to 1 depends on the document class: books will be split at chapters, but articles will get a section per page. And so on with lower levels.
2.6 HTML Code
The HTML code generated is technically XHTML Transitional, version 1.0 [2], using UTF-8 encoding. Some programs have (in this day and age) trouble importing XHTML, notably some popular word processors. To work around this problem and provide more flexible output in general you can output HTML 4.0:
$ elyxer.py --html document.lyx page-to-import.html
Again, technically the code generated is HTML 4.01 Transitional [3] using UTF-8 encoding. Both versions should pass the W3C tests [4]. If your particular web page doesn’t pass the tests, then it is a bug and it will be treated as such.
The --html option also activates the --simplemath option; see section 2.8↓: Math for details.
Character Encodings
For better browser compatibility, medium mathematical spaces are substituted in the output with midspaces — improving the output for some popular browsers. If you want your mathematical spaces back, just use the --unicode option:
$ elyxer.py --unicode document.lyx page-to-import.html
Check out the Math Showcase with Unicode to see the results. In the future other non-Unicode substitutions might be used.
In case you want to use the ISO-8859-15 encoding in your generated document, you can add the --iso885915 option:
$ elyxer.py --iso885915 document.lyx page.html
This will make eLyXer output a document with all non-ASCII characters encoded as ,   and so on. This encoding is similar to ISO-8859-1, also called Latin-1, but including the Euro sign. The Math Showcase (ISO-8859-15 edition) has been generated using this option.
Both encoding options can be combined with --html at will.
2.7 Internationalization
eLyXer is distributed along with a few translation files. They are automatically regenerated every time make is run, and reside in the folder po/. Internationalization is done using GNU gettext, so every locale is identified by a two-letter code (such as “en” for English and “es” for Spanish). There are two kinds of files: the text .po file (which can be found in po/my.po for locale “my”), and the binary .mo file (found in po/my/elyxer.po).
For internationalization to work properly, Linux distributors should take all binary .mo files and place them in the directory corresponding to locale files, which we will call $localedir. As the Python gettext page explains, this is distribution-dependent: for example on Debian $localedir is /usr/share/locale, so for locale “es” the correct route would be
/usr/share/locale/es/LC_MESSAGES/elyxer.mo
Windows distributors on the other hand should place files in %PYTHONHOME%\share\locale, for example for locale “es” on a machine where Python is in C:\python:
C:\python\share\locale\es\LC_MESSAGES\elyxer.mo
To generate a new translation file (we will use “my” as an example locale here, corresponding to Burmese): you need to have the GNU gettext package installed. Then go to the directory where elyxer.pot resides:
$ cd src/conf
and generate a .po file for your locale:
$ msginit --output-file=my.po --locale=my
Then move the file to the po/ directory:
$ mv my.po ../../po/
and start translating it to Burmese! Once you are done run make from the root directory:
$ ./make
and it will generate the file po/my/elyxer.mo. Finally, place this file in
$localedir/my/LC_MESSAGES/elyxer.mo
and you are done.
2.8 Math
Math equations are an important part of what takes LyX apart from other editors, since it supports the full LaTeX feature set — that is, about everything under the sun. Unfortunately, math support is hard to get right. Many developers are focusing on MathML, but at the time of this writing (Q2 2010) support on some common browsers is still missing.
eLyXer follows its usual minimalistic approach and doesn’t try to be everything to everybody — instead, it supports out of the box a set of usual constructs (fraction, square root) and tries to simulate others (binomial, overbrace). See the Math showcase for yourself and learn what eLyXer supports and what not.
For more sophisticated math equations there are a couple of advanced features.
MathJax
The first option is to use MathJax, which is as simple as using the option --mathjax:
$ elyxer.py --mathjax remote math.lyx math-mathjax-remote.html
The remote argument tells MathJax to access the MathJax library remotely on the MathJax CDN. (You should always comply with their terms of service.) See the Math showcase (MathJax remote edition) to check the results.
In case you need to go outside the terms of service, or you want the content to be accessible offline, you can always use a local copy of MathJax. Just use the URL of the repository as an argument to the --mathjax option:
$ elyxer.py --mathjax MathJax/ math.lyx math-mathjax-local.html
This way eLyXer uses the given URL (in the example MathJax/) to load MathJax from and set it up. Although some code needs to be hosted on the same site as the pages, MathJax uses a feature called web-fonts which can be downloaded from a public server; this is quite easier to host. See the Math showcase (MathJax edition) to see how MathJax fares with eLyXer.
Something to note is that MathJax is a JavaScript library; all rendering is done client-side by the user’s browser. This has quite a few advantages:
- Math processing on the server is quite light; equations are basically surrounded by a special tag and left in TeX form.
- For developers: integration of these libraries is very easy. It took just a few days to integrate both libraries with eLyXer.
- MathJax is improving all the time thanks to the efforts of Davide P. Cervone and the rest of the developer team; eLyXer and its users reap the benefits readily.
- The client browser already knows its abilities, and can choose the rendering method it considers to be the best. MathJax can even choose between MathML and HTML+CSS at page rendering time, showing MathML on fancier browsers and simpler HTML where it is not available.
It also brings some disadvantages:
- With the remote argument, JavaScript code resides at a remote server and your users will need online access to view the maths.
- If MathJax is accessed locally you need to also host the code for MathJax. (Web fonts used in MathJax can at least be hosted elsewhere, so publishers do not need to also host the fonts package, but this hasn’t still been used in eLyXer.)
- And of course it takes some time to render everything on the client, which can degrade the user experience on older machines.
Publishers should carefully consider pros and cons before deciding what to use.
Google Charts
Google Charts is an online service which generates images that contain charts and other stuff; it can also generate TeX formulas. eLyXer can use it using the option --googlecharts:
$ elyxer.py --googlecharts math.lyx math-googlecharts.html
There are some limitations to Google Charts: no macros, formulas cannot exceed 200 characters, and the supported command set is limited (commands in text mode, for instance, are out of bounds). Also, generated images can be hard to align vertically — by default they are middle-aligned, but some small characters or superscripted formulas can look weird. But this option can be a quick&dirty way of showing math for older or unsupported browsers.
Brackets and Limits
Fancy math structures are generated by default: arrays and binomials are surrounded by multi-line Unicode brackets, limits in display mode are stacked above / below the symbol, and so on. When the option --simplemath is used eLyXer avoids such structures and just outputs enlarged regular symbols. It is also included in the --html option.
Check out the Math showcase (HTML edition) to see the results.
2.9 Footnotes
Footnote generation is surprisingly hard to get right in an HTML document. eLyXer has a fairly complete set of command line options to customize how footnotes are generated. Here we will use the aggregated option --footnotes "options" which can be used to specify any combination, but they can be turned on independently using --…foot. For instance: --footnotes number,margin is equivalent to --numberfoot --marginfoot.
Markers
The footnote is attached to a point of the text (the referring text) which is usually marked by a bit of text. The default behavior for the marker is to use a superscript letter surrounded by square brackets, in blue: [A]. The text can be changed to aligned text with --footnotes align: [A], so markers are not mistaken with other superscript constructs such as exponents (like ea).
Markers can also be converted to numbers using --footnotes number: [1]. Or, they can be switched over to symbols using --footnotes symbol: *. Available symbols are rotated from this sequence: * ** † ‡ § §§ ¶ ¶¶ # ##. All options can be combined. For instance, symbol markers look best when shown aligned; --footnotes align,symbol will show aligned symbolic markers such as * or †.
Position
Footnotes are supposed to appear at the foot of the page, but that is not always possible or practical in web pages. Huge pages make scrolling up and down quite uncomfortable, and remove the immediacy of having the note in the same page as the referring text.
There are a few alternatives: use the margin, show hovering text, or link to the note at the bottom of the page. eLyXer can use all three. --footnotes margin will place the notes at the margin, just as margin notes but with the addition of the footnote marker. While --footnotes hover will show hovering text when the mouse is placed on the marker; this is the default behavior. Note that hovering notes are converted into margin notes when printing.
When footnotes are shown at the end of the page with --footnotes end, footnote markers turn into links. The actual footnote at the end then contains a link back to the marker.
The most interesting part is that these three options can be combined at will: --footnotes margin,hover,end will show footnotes at the three possible locations. The most practical combination is probably --footnotes hover,end, which will show notes as hovering text and also at the end of the page. Note however that in this case notes will be printed twice (at the margin instead of hovering and at the end).
3 Work in Progress
As you can see eLyXer is a mature and tried package, but it has some rough edges.
3.1 Known Issues
The following issues (including bugs and missing features) are acknowledged. Some of them should be solved soon; others may take longer.
- On Mac OS X the output of a message with Unicode characters may cause an error. Workaround: run elyxer.py with the --quiet option.
- Some phonetic alphabet symbols are not well supported — if generated with LyX they only appear in a different color: [sample].
- Multi-column layouts are lost. This one is almost impossible to get right in CSS, so there are no plans to even try.
- Many BibTeX styles are missing. (They are quite trivial to add though.)
- ERT (bare TeX code) is ignored.
- Many AMS environments (like alignat, gather…) are not working or look strange — some non-AMS environments too.
- Images are never scaled above their nominal resolution. This is seldom needed if at all, so there are no plans to change it; if people really need the feature just let the author know so it can be added as an option.
3.2 Wish List
The following features have been requested by users; specific people are referenced by a couple of initials so they can recognize themselves while keeping some anonymity. (If you prefer that your initials do not to appear here at all just let me know.)
Queued features will be added at the next big release — the priority for each feature will be set by the number of users requesting it and date requested. Pending features need some assessment. Those marked as too complex have been evaluated as requiring too much work, but the decision might be reversed if there are enough people interested or a simple way to implement them is found. Once done, features are marked with the first release where they appear.
| Feature | Date | Users | Status |
| Understand \setcounter{section}{1} | 2010-05-15 | JB | 1.1.0 |
| Option to turn off title prefixes in TOC | 2010-07-10 | YG | 1.1.0 |
| Use BibLaTeX with eLyXer | 2010-09-14 | PJ, WE | Pending |
| Render change tracking: "Show changes in output" | 2010-09-18 | YG | 1.1.0 |
| Option for footnotes at the margin | 2010-09-21 | A | 1.1.0 |
| Output SVG as <img> tags (20↓) | 2010-09-22 | YG | Pending |
| EPUB output format (19↓) | 2010-09-23 | MJ, MG | Too complex |
| Option for footnotes at the end of each section | 2010-09-23 | MJ | 1.1.0 |
| Add more controls for image conversion (21↓) | 2010-10-02 | WE | 1.1.0 |
| Support for format 401 (Insert Horizontal Line) | 2010-10-06 | US | 1.1.2 |
| Parse contents of ERTs | 2010-10-06 | US, JW | 1.2.0 |
| Correct scaling of tables with relative sizes (e.g. %col) | 2010-10-09 | US | Pending |
| BibTeX: parse math formulas inside BibTeX files | 2010-10-16 | JA | 1.1.1 |
| BibTeX: display \url{} as an URL | 2010-10-16 | JA | 1.1.1 |
| Do not label bibliography items in comments | 2010-10-21 | JA | Pending |
| Unit tests should warn if ImageMagick not installed | 2010-10-24 | JA | Pending |
| Unit tests should run fine without PNG conversion tools | 2010-10-30 | JA | Pending |
| Option --imageformat copy to avoid converting images | 2010-11-12 | JD | 1.1.1 |
| Option to embed the CSS in the HTML file22↓ | 2010-11-23 | GM, JA | 1.1.1 |
| Display sub- and superscript aligned vertically (as in integrals) | 2010-11-23 | GM | 1.1.1 |
| Use Unicode large characters for sums, integrals, matrices… | 2010-12-07 | GM | 1.1.2 |
| Do not number captions in code listings | 2010-12-08 | DC | 1.2.0 |
| Support brushes for SyntaxHighlighter | 2010-12-10 | DC | Pending |
| Generate formula images using Google Charts | 2011-01-07 | ET | 1.2.1 |
| Output reference arrows as CSS pseudo-elements | 2011-01-12 | GM | Pending |
| Include part names in --splitpart navigation header | 2011-01-15 | AJ | 1.2.1 |
| Merge options --toc and --toctarget into --tocfor | 2010-01-17 | JA | 1.2.1 |
| Make --splitpart and --tocfor work together | 2010-01-17 | JA, TP | 1.2.1 |
| Generate named references (equivalent to \nameref) | 2011-01-19 | TP | 1.2.1 |
| Do not generate entries when index or nomenclature are missing | 2011-01-19 | TP | Queued |
| Do not output unknown commands in red except in --debug | 2011-02-22 | JA | Queued |
| Output equations as images | 2011-05-31 | GK | Pending |
| Parse modules for custom Flex CharStyles | 2011-06-08 | MG | Pending |
| Convert several files with a single command | 2011-06-01 | PF | Pending |
| Export slides as HTML5 presentation | 2011-06-28 | RK | Pending |
| Add an option to remove navigation bars | 2011-06-29 | AH | Pending |
Some features require further explanations.
EPUB output format
The EPUB management package calibre does not output valid EPUB documents when converted from eLyXer HTML files, at least according to the Threepress validator.
This is a complex feature request; calibre does minimal formatting in its EPUB conversion, so making it generate valid EPUB documents requires changing deeply how eLyXer outputs XHTML. Lots of help would be needed to get this working.
Output SVG as <img> tags
This feature would be most welcome from the part of the author. Unfortunately, Firefox alone from the major browsers refuses to render <img> tags correctly for SVG. According to bug #276431, this was fixed on 2010-09-08, so the next version should do the right thing; at that point this feature will be queued for inclusion.
You can check out how your browser does with SVG images with this SVG test page.
More controls for image conversion
eLyXer uses ImageMagick to convert images. Some images (in EPS format, for example) do have blank borders, or they come in varied sizes. It would be nice to remove blank borders and have some kind of unified resolution in the conversion, which would be passed to ImageMagick.
As of 1.1.0, the improvements include using ps:use-cropbox=true in ImageMagick for PostScript and EPS images. Unified resolution has not been added as it might collide with picture density, but suggestions are welcome.
CSS controls
Proposed by JRAS on the elyxer-users mailing list, the following is a direct quote of his message.
“[…]A mixed solution for CSS styles:
- The essential minimum css for math formatting (a compacted version of a math.css subset) included directly inside HTML head.
- Then a call to download the on-line full CSS, that can repeat the minimum already included math.css (from item 1) plus some other styles. The default can be changed by --css command line option.
- A new option (--addcss) to add another CSS defined by the user. For example, to only redefine some styles from the default, etc.
The styles should be included in that order (using the "cascading" property). Item 1 is fixed in every HTML file. Item 2 is always added and by default pointing to the eLyXer on-line css, but it can be changed by option --css to another url or file. Item 3 is optional and its url would be added after the other two items, only if the --addcss option was used in conversion.”
As of 1.1.1, an option --embedcss has been added which allows embedding one or more custom CSS files into the resulting HTML document. Also, --css can be repeated as many times as desired to use several CSS files.
3.3 Contact Information
If your problem does not appear in the above list, please let the author know; you can find him at elyxer@gmail.com. In the words of Rich Talley: “the tool’s author really likes getting challenging documents and making eLyXer work with them”. You can send your sample documents and we will try to make eLyXer convert them acceptably. Any documents sent will be treated with the utmost confidentiality.
You can also join the mailing list to discuss any information related to eLyXer. The author monitors the official LyX lists for mentions of eLyXer. Bugs can also be reported at the Savannah page.
3.4 Extending eLyXer
eLyXer should now support most LyX features; but sometimes it will ignore a command, sometimes it will signal it, and it might even refuse to work with certain documents. What can you do if eLyXer does not work with your LyX file? Worry not! Its flexible approach to processing allows anyone to write support for the missing commands.
eLyXer is written in Python so that it does not need to be compiled; its code is interpreted on the fly. See the accompanying developer guide to learn how to extend eLyXer for your own purposes. If you know how to program in Python it should not be difficult to support other LyX features. If you don’t your best bet is to ask the author.
4 FAQ
Q: What versions of LyX are supported?
A: The tool should work with all LyX versions from 1.5.5 to the latest and greatest. It has been tested on Linux, Mac OS X and Windows.
Q: There are indeed a ton of similar projects over the web. Why add another one?
A: The four tools supported by LyX (tex4ht, hevea, tth and latex2html) gave inferior results in 2009, and were quite inflexible. The author found the need for a good converter, while at the same time acknowledging the difficulty of the problem.
Q: Speaking of that: why build a LyX to HTML converter, instead of a more generic LaTeX to HTML converter?
A: The problem space is quite simplified, and therefore progress is much faster. To make it even easier eLyXer has historically centered on the subset of LyX functionality that is useful to most LyX users, leaving the rest for a later stage. Nowadays eLyXer aims to support the full LyX feature set.
Q: What can we expect from the tool in the future?
A: eLyXer should fulfill the needs of 99% of LyX users in the short term. It has also learned a couple of tricks of its own such as page segmenting. Eventually it could be distributed along with LyX as part of the standard installer.
Q: Why did you leave out my favorite feature <insert random LyX command here>?
A: In short, because nobody asked for it. Every feature which has been requested (either to me personally or to the list) has been tended to, unless it was too far out or I forgot about it. At this point of development every missing LyX feature will be considered a high priority item for the next version, if at all possible to implement.
Q: My document changed its appearance without my intervention. Was it black magic, elves or what?
A: It probably uses the online CSS file, which is regularly updated. See section 2.2↑ for details.
Q: Why use an online CSS, instead of placing the CSS file in the same directory as the converted file?
A: There were pros and cons. An online CSS resource allowed me to update it for everyone at the same time, but might make it more difficult for people without an internet connection; local CSS files are more flexible but can also be confusing to novice users. In the end the online solution was preferred, with the --css option as a fallback.
Q: My MathJax pages are not rendering correctly; equations are silently ignored.
A: Check that MathJax is installed on the same server as your pages; for security reasons the browser’s “same-origin” policy mandates that JavaScript can only be loaded from the same site as the original page. Also make sure that JavaScript is enabled on the browser.
Q: I found a bug, what should I do?
A: Just send it to the author at elyxer@gmail.com. You can also report it to the Savannah interface.
References
[1] WordReference.com: “definition of elixir”, accessed March 2009. http://www.wordreference.com/definition/elixir
[2] W3C: “XHTML™ 1.0 The Extensible HyperText Markup Language (Second Edition)”, revised 1 August 2002. http://www.w3.org/TR/xhtml1/
[3] W3C: “HTML 4.01 Specification”, 24 December 1999. http://www.w3.org/TR/REC-html40/
[4] W3C: “Markup Validation Service”, accessed March 2009. http://validator.w3.org/